Tin Công Nghệ Cao
Media chuyên về thế giới công nghệ cao, Phần cứng và Trò chơi, đưa ra các so sánh, hướng dẫn mua hàng và xếp hạng khách quan, đảm bảo mức giá hấp dẫn và sự lựa chọn tốt nhất nhờ một nhóm những người đam mê.
Bài viết được xem nhiều nhất của chúng tôi





Tầm nhìn của chúng tôi về tin tức Công nghệ cao
Cộng đồng
Neuf.tv là một phương tiện truyền thông cộng đồng, một phần lớn độc giả của chúng tôi liên hệ với chúng tôi để thảo luận về các chủ đề sẽ được đề cập!
Chuyên nghiệp
Các bài viết nổi bật của chúng tôi được viết bởi các chuyên gia trong ngành để giúp bạn cập nhật những tin tức mới nhất!
Nhanh
Chúng tôi đang theo dõi bất kỳ thông tin thú vị nào, hãy đảm bảo rằng tất cả các tin tức mới nhất đều có trên Neuf.tv.
Tin mới nhất

8 dấu hiệu nhận biết màn hình của bạn sắp chết
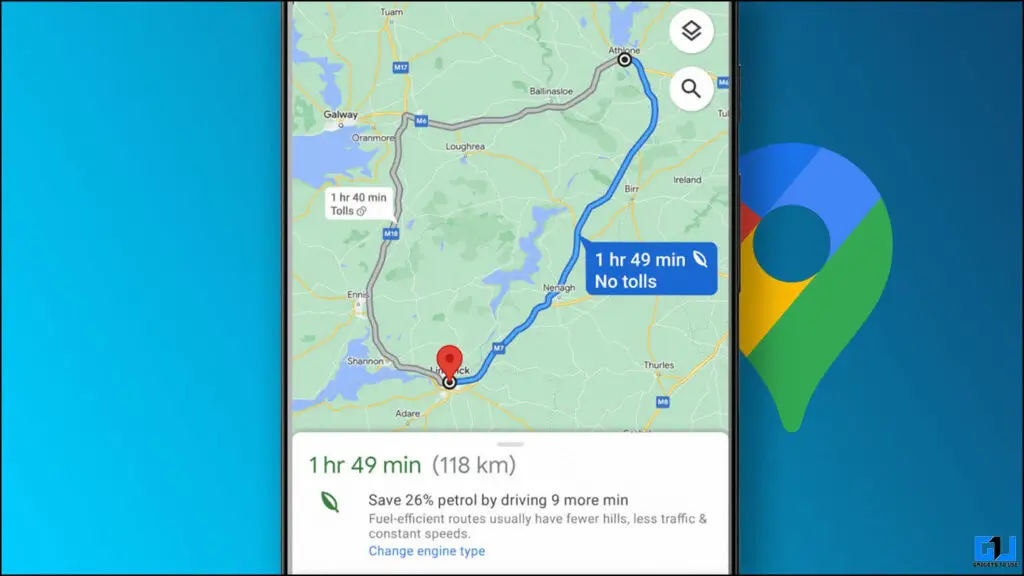
Cách tìm tuyến đường tiết kiệm nhiên liệu trên Google Maps

Cách khắc phục lỗi tải xuống trình điều khiển NVIDIA GeForce

Cách xóa bộ nhớ đệm trên TV thông minh LG

8 phương pháp khắc phục Bluetooth không hoạt động trên điện thoại Android của bạn
