Högteknologiska nyheter
Media specialiserade på en värld av högteknologi, hårdvara och spel, erbjuder jämförelser, köpguider och objektiva rankningar, garanterar attraktiva priser och de bästa valen tack vare ett team av entusiaster.
Våra mest sedda artiklar





Vår vision av högteknologiska nyheter
communautaire
Neuf.tv är ett samhällsmedie, kontaktar en stor del av våra läsare oss för att diskutera de ämnen som ska tas upp!
Professional
Våra funktionsartiklar är skrivna av branschexperter för att hålla dig uppdaterad med de senaste nyheterna!
rapide
Vi är på jakt efter all intressant information, se till att alla de senaste nyheterna finns på Neuf.tv.
Senaste nytt

8 tecken på att din monitor håller på att dö
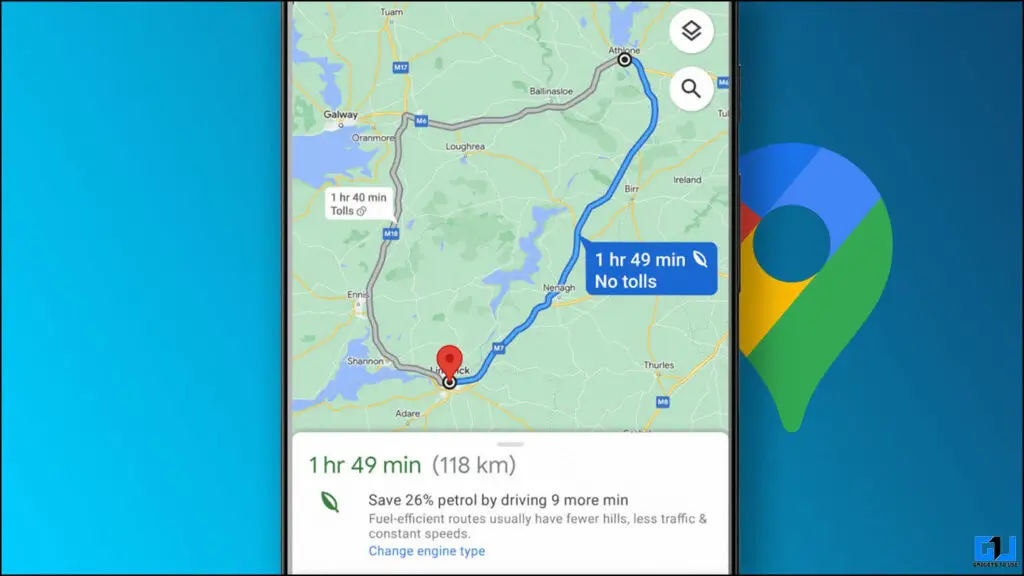
Hur man hittar bränsleeffektiva rutter på Google Maps

Hur man åtgärdar NVIDIA GeForce-drivrutinsnedladdningsfel

Hur man rensar cacheminnet på en LG Smart TV

8 metoder för att fixa Bluetooth som inte fungerar på din Android-telefon
