Notícias de alta tecnologia
Mídia especializada no mundo da alta tecnologia, Hardware e Gaming, oferecendo comparações, guias de compra e rankings objetivos, garantindo preços atrativos e as melhores escolhas graças a uma equipe de entusiastas.
Nossos artigos mais vistos





Nossa visão de notícias de alta tecnologia
Comunidade
Neuf.tv é uma mídia comunitária, grande parte dos nossos leitores nos contata para discutir os temas a serem abordados!
Profissional
Nossos artigos de destaque são escritos por especialistas do setor para mantê-lo atualizado com as últimas notícias!
Rapide
Estamos atentos a qualquer informação interessante, certifique-se de que todas as últimas notícias estão presentes no Neuf.tv.
Últimas notícias

8 sinais reveladores de que seu monitor está morrendo
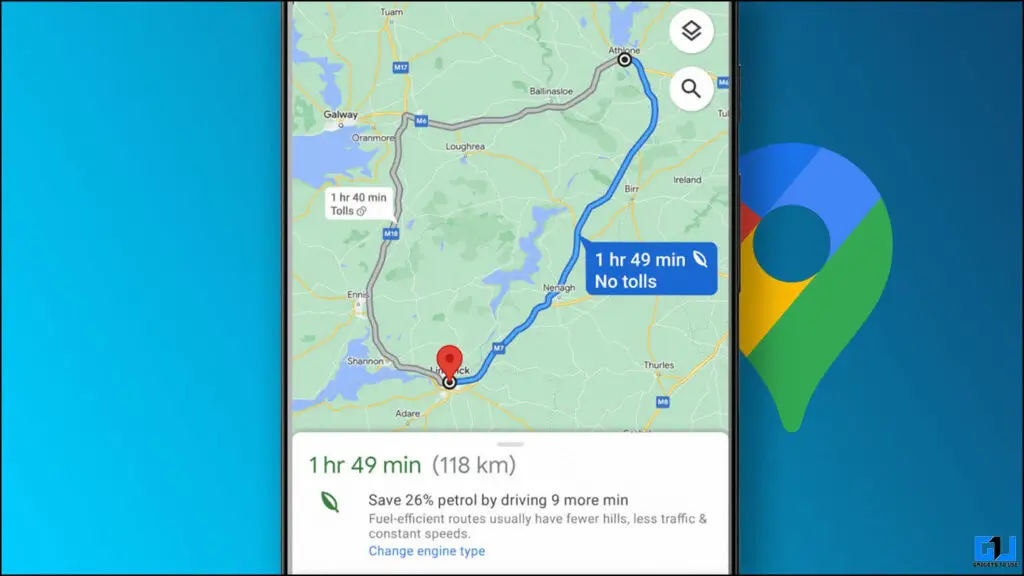
Como encontrar rotas com baixo consumo de combustível no Google Maps

Como corrigir falhas de download do driver NVIDIA GeForce

Como limpar o cache em uma LG Smart TV

8 métodos para consertar o Bluetooth que não funciona em seu telefone Android
