Nowości zaawansowane technologicznie
Media specjalizujące się w świecie high-tech, Hardware i Gaming, oferujące porównania, poradniki zakupowe i obiektywne rankingi, gwarantujące atrakcyjne ceny i najlepszy wybór dzięki zespołowi pasjonatów.
Nasze najczęściej oglądane artykuły





Nasza wizja wiadomości high-tech
Wspólnota
Neuf.tv jest mediami społecznościowymi, duża część naszych czytelników kontaktuje się z nami w celu przedyskutowania tematów do poruszenia!
Profesjonalny
Nasze artykuły fabularne są pisane przez ekspertów branżowych, abyś był na bieżąco z najnowszymi wiadomościami!
Szybko
Szukamy ciekawych informacji, bądź pewny, że wszystkie najnowsze wiadomości są na bieżąco Neuf.tv.
Najnowsze wiadomości

8 charakterystycznych oznak, że Twój monitor umiera
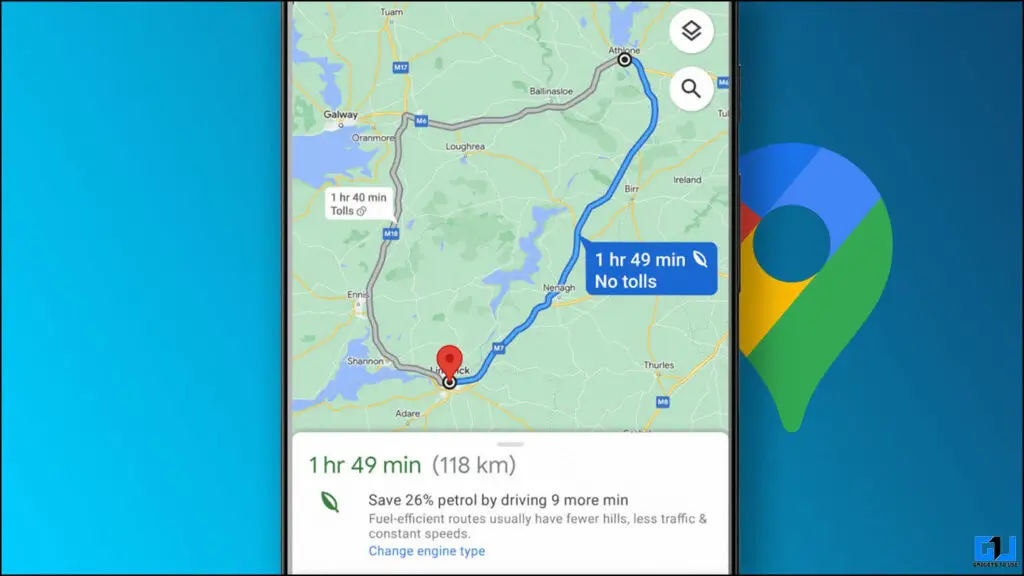
Jak znaleźć oszczędne trasy w Mapach Google

Jak naprawić błędy pobierania sterownika NVIDIA GeForce

Jak wyczyścić pamięć podręczną w telewizorze LG Smart TV

8 metod naprawienia niedziałającego Bluetootha na telefonie z Androidem
