Hightech nieuws
Media gespecialiseerd in de wereld van hightech, hardware en gaming, biedt vergelijkingen, koopgidsen en objectieve ranglijsten, garandeert aantrekkelijke prijzen en de beste keuzes dankzij een team van enthousiastelingen.
Onze meest bekeken artikelen





Onze visie op High Tech nieuws
gemeentelijk
Neuf.tv is een gemeenschapsmedia, een groot deel van onze lezers neemt contact met ons op om de te behandelen onderwerpen te bespreken!
Professioneel
Onze hoofdartikelen zijn geschreven door experts uit de industrie om u op de hoogte te houden van het laatste nieuws!
Snel
We zijn op zoek naar interessante informatie, zorg ervoor dat al het laatste nieuws aanwezig is op Neuf.tv.
Laatste nieuws

8 veelbetekenende signalen dat uw monitor het begeeft
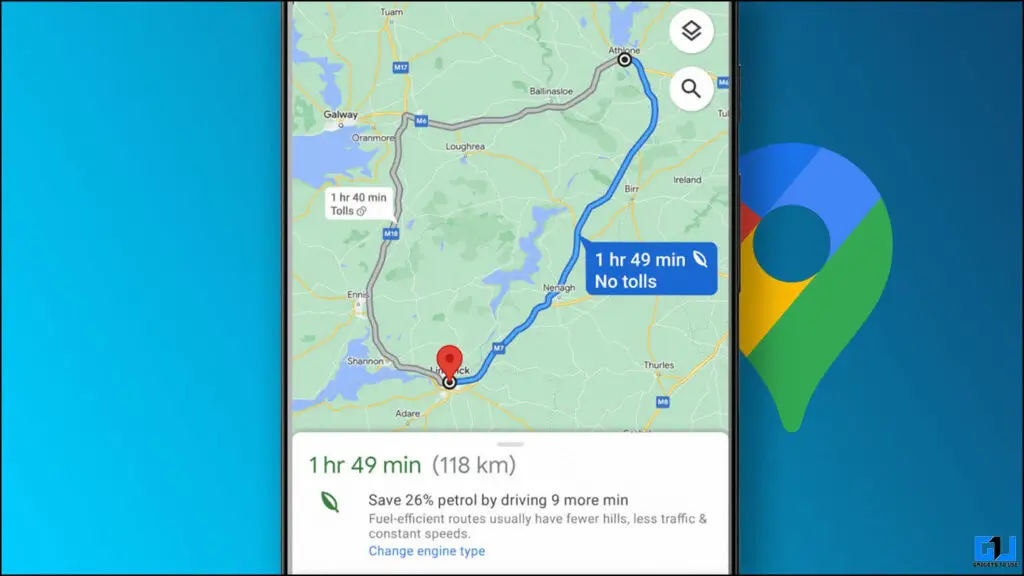
Hoe u brandstofefficiënte routes kunt vinden op Google Maps

Hoe u problemen met het downloaden van NVIDIA GeForce-stuurprogramma's kunt oplossen

Cache wissen op een LG Smart TV

8 methoden om te verhelpen dat Bluetooth niet werkt op uw Android-telefoon
