L’Actualité High-Tech
Média spécialisé dans l’univers de l’high-tech, l’Hardware et du Gaming, offrant des comparatifs, guides d’achat et classements objectifs, garantissant des prix attractifs et les meilleurs choix grâce à une équipe de passionnée.
Nos Articles Les Plus Consultés





Notre vision de l’actualité High-Tech
Communautaire
Neuf.tv est un média communautaire, une grande partie de nos lecteurs nous contactent pour discuter des sujets à aborder !
Professionnel
Nos articles principaux sont rédigés par des experts du secteur pour vous tenir informé des dernières actus !
Rapide
Nous sommes à l’affut de toute information intéressante, soyez sûr que toutes les dernières actualités sont présentes sur Neuf.tv.
Les dernières Actualités

8 signes révélateurs que votre moniteur est en train de mourir
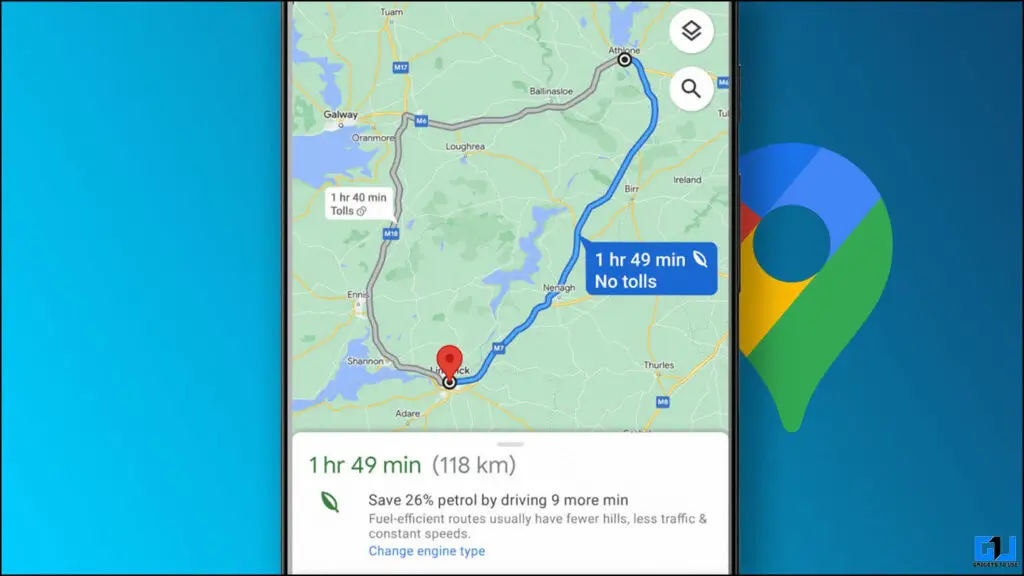
Comment trouver des itinéraires économes en carburant sur Google Maps

Comment réparer les échecs de téléchargement du pilote NVIDIA GeForce

Comment vider le cache sur un téléviseur intelligent LG

8 méthodes pour réparer Bluetooth qui ne fonctionne pas sur votre téléphone Android
